머신러닝이란?
애플리케이션을 수정하지 않고도 데이터를 기반으로 패턴을 학습하고 결과를 추론하는 알고리즘 기법
기존의 소프트웨어 코드만으로 해결하기 어려웠던 많은 문제점을 해결 가능
인간의 인지능력만이 해결 가능하다고 생각했던 분야에서 적용하며 발전하고 있음 (데이터 마이닝, 영상인식, 음성인식, 자연어 처리 등에 머신러닝 적용)
필요성
복잡한 문제를 데이터 기반으로 패턴을 인지해 해결
분류
| 지도 학습 | 비지도 학습 |
| 명확한 결정값이 주어진 데이터를 학습 분류 회귀 시각/음성 감지/인지 |
결정값이 주어지지 않는 데이터를 학습 군집화(클러스터링) 자원 축소 |
단점
- 데이터에 너무 의존적
- 실제 환경 데이터 적용 시 과적합 되기 쉬움
- 데이터만 집어 넣으면 자동으로 최적화된 결과를 도출해 내지 않음
(특정 경우 개발자 코드보다 정확도가 떨어지기도 함)
- 끊임없이 개선하기 위한 노력이 필요하기 때문에 고급 능력이 필요함
특징과 장점
R언어와 비교
| R언어 | python |
| 통계 전용 프로그램 언어 다양하고 많은 통계 패키지 보유가 장점 |
개발 언어 쉽고 뒤어난 개발 생산성 많은 라이브러리 지원 |
python과 machine learning - 뛰어난 확장성, 연계, 호환성
다양한 어플리케이션 개발도 가능하고 연계도 쉬움 - 기존 어플리케이션에 쉽게 스며들 수 있음
유수의 deep learning framework가 python 기반으로 작성 됨 (but, tensorflow 제외 - 성능 때문에 c/c++로 작성)
파이썬 머신러닝 생태계를 구성하는 주요 패키지
NumPy 배열/선형대수 패키지
pandas 2차원 데이터 핸들링
Jupyter 대화형 파이썬 툴 (필기하듯이 코드 애플리케이션 수행을 끊어서 할 수 있음)
툴 다운로드

Jupyter Notebook
대화형 파이썬 툴
전체 프로그램에서 특정 코드 영역별로 개별 수행을 지원 - 영역별로 코드 이해가 매우 명확해짐

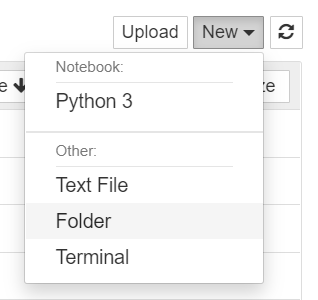


rename 한 디렉토리를 누르면 empty라고 뜨는데
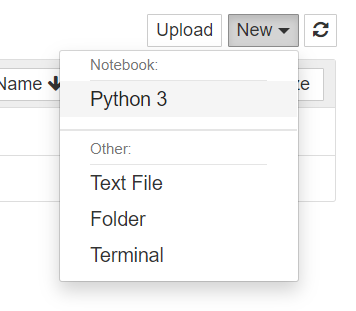
여기서 python3를 누르면

이렇게 코드 작성할 수 있도록 창이 바뀐다.
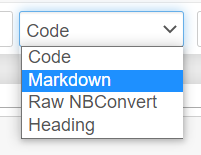
보통 code와 markdown만 주로 쓴다고 한다.
code는 실행을 위한 코드이고, markdown은 설명을 위한 코드이다.
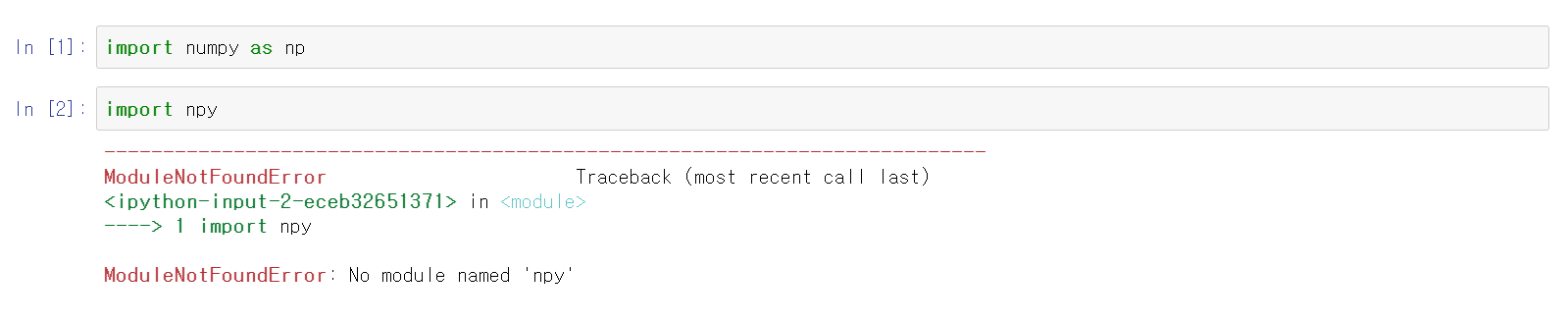
코드가 오류가 없으면 1번째 줄 처럼 정상적으로 실행되지만, 오류가 있을 경우 2번째 줄 처럼 발생한 오류의 내용이 함게 뜬다.

한 줄을 없애면 없앤 줄 다음 줄부터 나타난다.(7번째 줄을 삭제한 후 새 줄에다가 코드 작성 시 8번째 줄이 나타남)

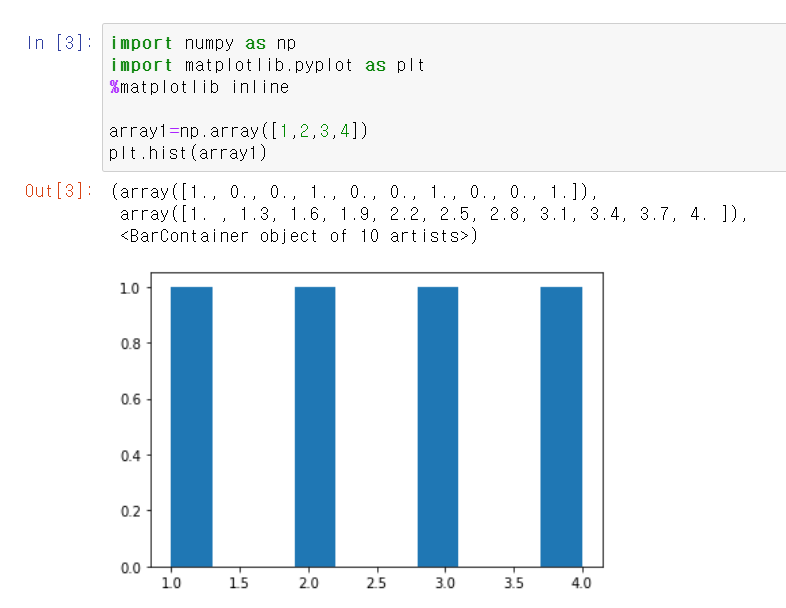
넘파이와 판다스의 중요성
다양한 데이터의 처리 부분을 담당함
사이킷런이 넘파이 기반에서 작성되어 넘파이를 이해하지 못하면 구현에서 힘들 수 있음
+) 공부방법 : 넘파이와 판다스에 대한 기본 프레임워크와 중요 API만 습득하고, ㅇ리단 코드와 부딪쳐 가면서 모르는 API에 대해서는 인터넷 자료를 통해 습득하기
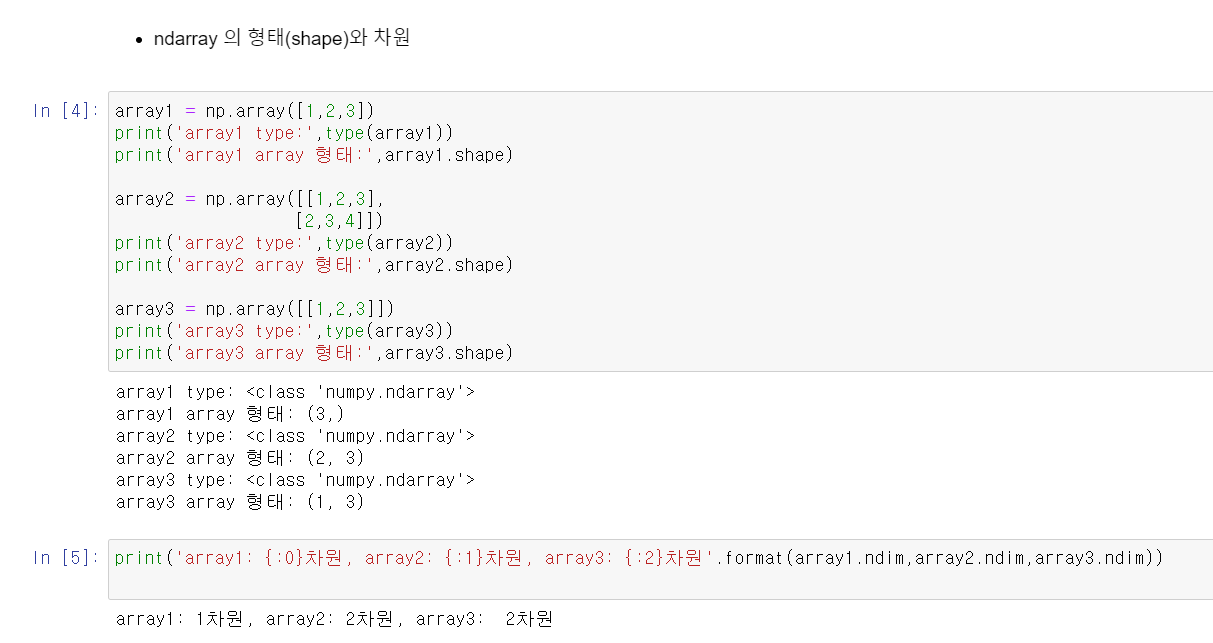
넘파이 ndarray
ndarray : N차원(Dimemsion) 배열(Array) 객체
다양한 연산을 ndarray 기반에서 제공
인자로 주로 파이썬 list 또는 ndarray 입력
ndarray 내의 데이터 타입은 그 연산의 같은 데이터 타입만 가능
데이터 타입은 ndarray.dtype으로 확인 가능
타입 변환 시 변경을 원하는 타입을 astype()에 인자로 입력 - 대용량 데이터 사용 시 형변환 자주 사용 (메모리 절약 위해)
axis 0 :행
axis 1 : 열


'Machine learning' 카테고리의 다른 글
| [머신러닝] 평가 (0) | 2021.07.27 |
|---|---|
| 사이킷런으로 시작하는 머신러닝 실습 - 붓꽃 품종 예측/타이타닉 생존자 예측 (0) | 2021.07.18 |


댓글