[파이썬 머신러닝 완벽 가이드 - 권철민] 책을 참고로 공부한 내용입니다.
사이킷런이란?
파이썬 머신러닝 라이브러리 중 가장 많이 사용되는 라이브러리
특징
- 파이썬 기반의 다른 머신러닝 패키지도 사이킷런 스타일의 API를 지향할 정도로 쉽고 가장 파이썬스러운 API 제공
- 머신러닝을 위한 매우 다양한 알고리즘과 개발을 위한 편리한 프레임워크와 API를 제공
- 오랜 기간 실전 환경에서 검증됐으며, 매우 많은 환경에서 사용되는 성숙한 라이브러리임
아나콘다를 설치하면 기본으로 사이킷런까지 설치됨
1. 붓꽃 품종 예측하기
붓꽃 데이터 세트는 꽃잎의 길이와 너비, 꽃받침의 길이와 너비 피처(Feature)를 기반으로 꽃의 품종을 예측하기 위한 것
분류는 대표적인 지도학습 방법의 하나이다.
지도학습은 학습을 위한 다양한 피처와 분류 결정값인 레이블 데이터로 모델을 학습한 뒤, 별도의 테스트 데이터 세트에서 미지의 레이블을 예측한다.
사이킷런 패키지 내의 모듈명은 sklearn으로 시작해야한다.

붓꽃 데이터 세트를 생성하는 데는 load_iris()를 이용하며, ML 알고리즘은 의사 결정 트리 알고리즘으로 이를 구현한 DecisionTreeClassifier를 적용한다. 데이터 세트를 학습 데이터와 테스트 데이터로 분리하는 데는 train_test_split() 함수를 사용한다.

load_iris() 함수를 이용해 붓꽃 데이터 세트를 로딩한 후, 피처들과 데이터 값이 어떻게 구성돼 있는지 확인하기 위해 DataFrame으로 변환해보자

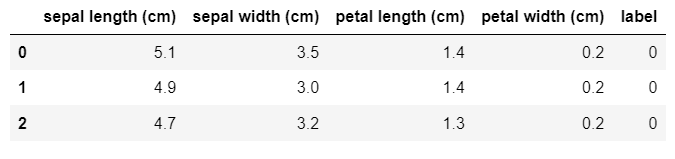
피처에는 sepal length, sepal width, petal length, petal width가 있다. 레이블은 0, 1, 2 세 가지 값으로 돼 있으며 0이 Setosa, 1이 versicolor, 2가 virginica 품종을 의미한다.
다음으로 학습용 데이터와 테스트용 데이터를 분리해보자. 학습 데이터로 학습되 모델이 얼마나 뛰어난 성능을 가지는지 평가하려면 테스트 데이터 세트가 필요하기 때문이다. 이를위해 train_test_split() API를 사용한다. 이는 학습 데이터와 테스트 데이터를 test_size 파라미터 입력 값의 비율로 쉽게 분할할 수 있다.

확보한 학습 데이터를 기반으로 의사 결정 트리를 이용해 학습과 예측을 수행하자.
사이킷런의 의사 결정 트리 클래스인 DecisionTreeClassifier를 객체로 생성한다. 생성된 객체의 fit() 메서드에 학습용 피처 데이터 속성과 결정값 데이터 세트를 입력해 호출하여 학습을 수행한다.

학습된 DecisionTreeClassifier 객체를 이용해 예측을 수행하자
예측은 반드시 학습 데이터가 아닌 다른 데이터를 사용해야 하며, 일반적으로 테스트 데이터 세트를 이용한다.

예측 결과를 기반으로 의사 결정 트리 기반의 DecisionTreeClassifier의 예측 성능을 평가해보자
정확도는 예측 결과가 실제 레이블 값과 얼마나 정확하게 맞는지를 평가하는 지표로 정확도를 측정해보려고 한다.
정확도 측정을 위해 accuracy_score()함수를 사용한다.

2. 사이킷런으로 수행하는 타이타닉 생존자 예측
타이타닉 생존자 예측은 머신러닝에 입문하는 데이터 분석가/과학자를 위한 기초 예제로 제공되고 있다.
타이타닉 탑승자 데이터는 아래와 같다.
- Passengerid: 탑승자 데이터 일련번호
- survived : 생존 여부, 0=사망, 1=생존
- pclass : 티켓의 선실 등급, 1=일등석, 2=이등석, 3=삼등석
- sex : 탑승자 성별
- name : 탑승자 이름
- Age : 탑승자 나이
- sibsp : 같이 탑승한 형제자매 또는 배우자 인원수
- parch : 같이 탑승한 부모님 또는 어린이 인원수
- ticket : 티켓 번호
- fare : 요금
- cabin : 선실 번호
- embarked : 중간 정착 항구
판다스의 read_csv()를 이용해 DataFrame으로 로딩한다.


로딩된 데이터 칼럼 타입을 확인해보자
DataFrame의 info() 메서드를 통해 확인이 가능하다.
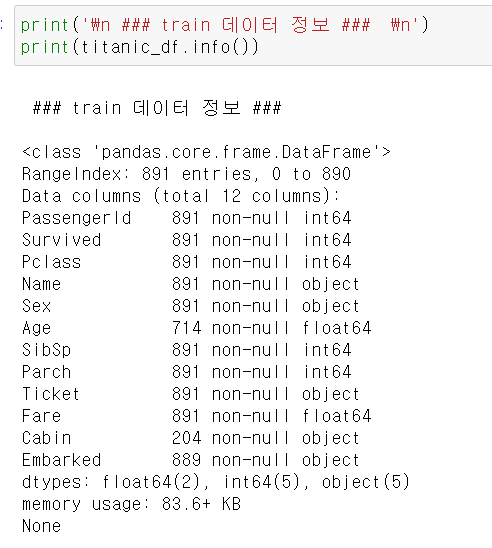
결과 값을 보면 Age, Cabin, Embarked 칼럼은 각각 714개, 204개, 889개의 Not Null 값을 가지고 있으므로 각각 177개, 608개, 2개의 Null 값을 가지고 있다.
사이킷런 머신러닝 알고리즘은 Null 값을 허용하지 않으므로 Null 값을 어떻게 처리할지 결정해야 한다.
여기서는 DataFrame의 fillna() 함수를 이용해 간단하게 Null 값을 평균 또는 고정 값으로 변경하려고 한다.
Age의 경우는 평균 나이, 나머지 칼럼은 'N' 값으로 변경한다. 그 다음 모든 칼럼의 Null 값이 없는지 다시 확인하겠다.

이제 남아있는 문자열 피처인 Sex, Cabin, Embarked들의 값 분류를 살펴보자

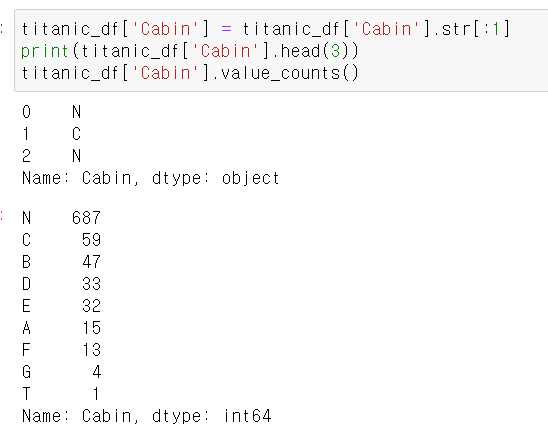
그 결과 Cabin의 경우 N이 687건으로 가장 많은 것도 특이하지만, 속성값이 제대로 정리가 되지 않은 것 같다.
다시 Cabin 속성의 경우 앞 문자만 추출해보자.
그리고 머신러닝 알고리즘을 적용해 예측을 수행하기 전에 데이터를 먼저 탐색해보려고 한다.
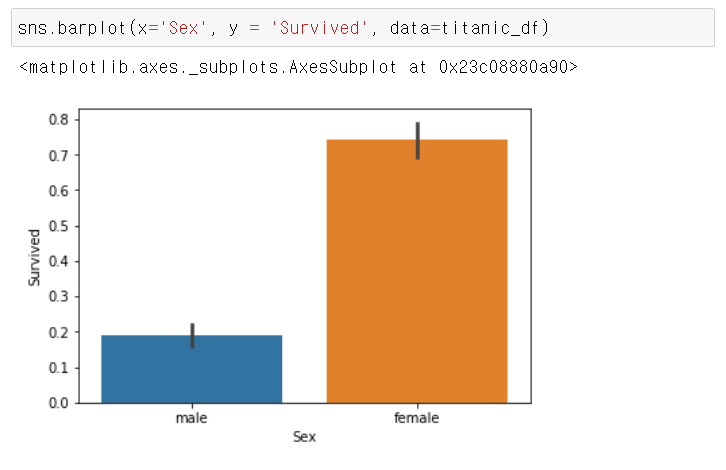
첫 번째로 어떤 유형의 승객이 생존 확률이 높았는지 확인해보자. 그 중에서도 성별이 생존 확률에 어떤 영향을 미쳤는지, 성별에 따른 생존자 수를 비교해보았다.
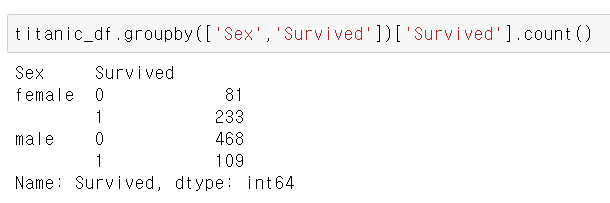
탑승객은 남자가 577명, 여자가 314명으로 남자가 더 많았다. 여자는 생존자가 233명으로 약 74.2%가 생존했지만, 남자의 경우 생존자가 109명으로 약 18.8%가 생존했다.
시각화는 시본 패키지를 이용했다.
부자와 가난한 사람 간의 생존 확률도 살펴보자
부는 객실 등급으로 측정하였다.
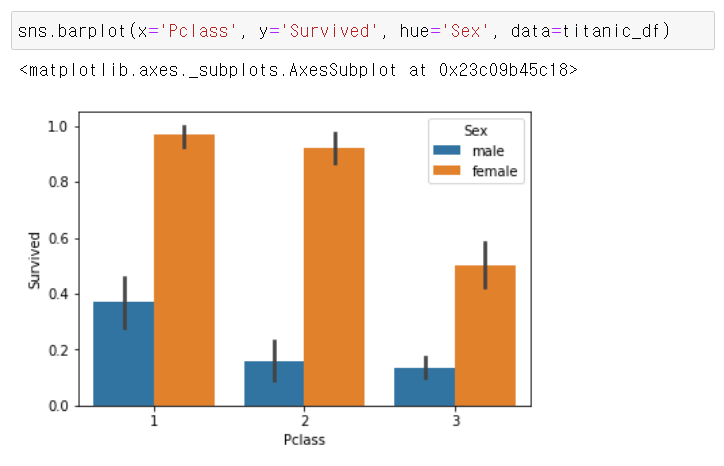
여성의 경우 일, 이등실에 따른 생존 확률의 차이는 크지 않으나, 삼등실의 경우 생존 확률이 상대적으로 많이 떨어짐을 알 수 있다. 남성의 경우 일등실의 생존확률이 이, 삼등실의 생존 확률보다 월등히 높다.
이번에는 Age에 다른 생존 확률도 알아보자

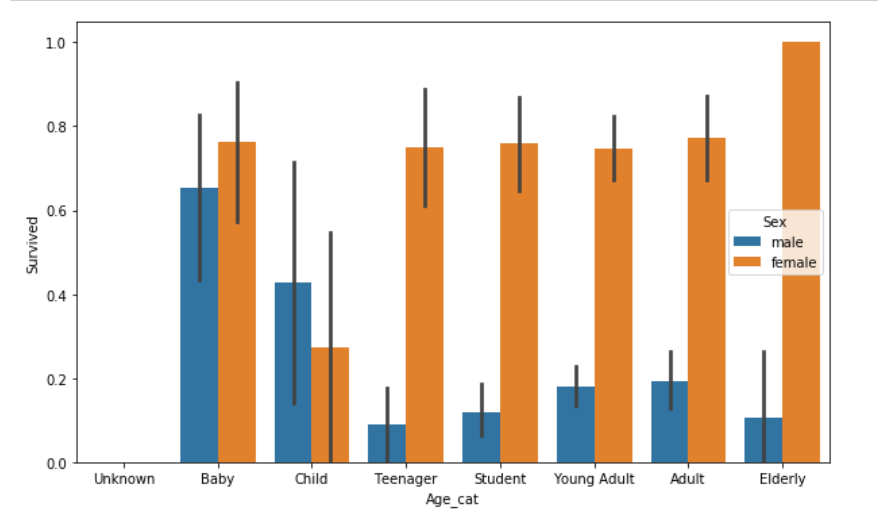
이제까지 분석 결과를 보면 Sex, Age, PClass 등이 중요하게 생존을 좌우하는 피처임을 확인할 수 있었다.
이제 남아있는 문자열 카테고리 피처를 숫자형 카테고리 피처로 변환하려고 한다.
인코딩은 사이킷런의 LabelEncoder 클래스를 이용했다. LaberEncoder 객체는 카테고리 값의 유형 수에 따라 숫자 값으로 변환해준다.
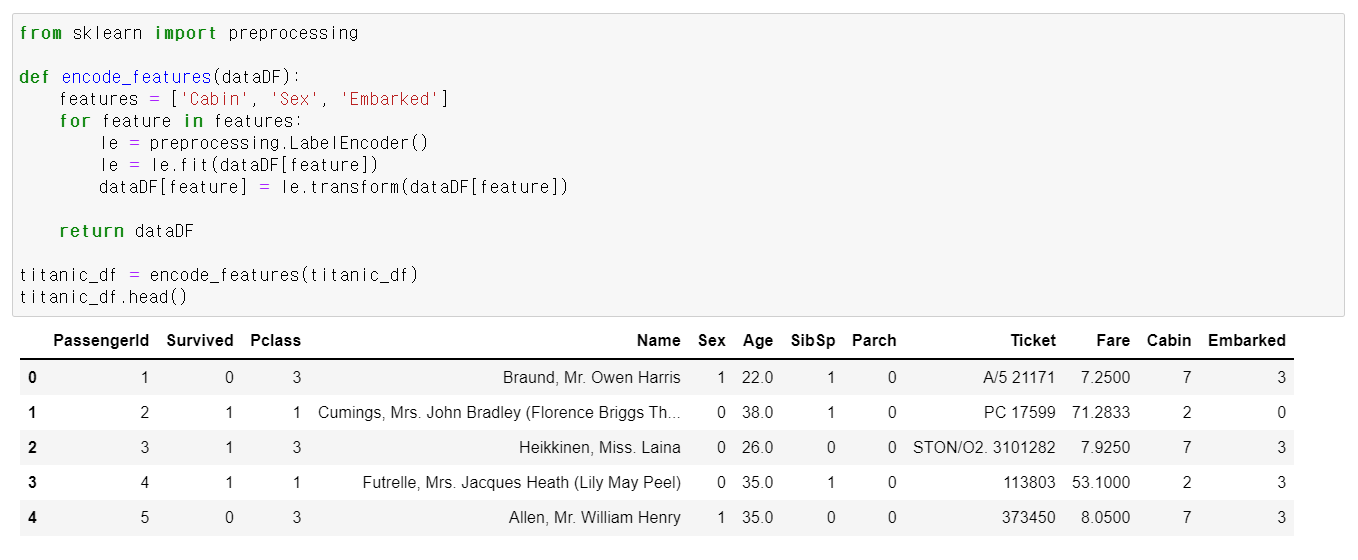
Sex, Cabin, Embarked 속성이 숫자형으로 바뀐 것을 알 수 있다.
지금까지 피처를 가공한 내역을 정리하고, 이를 함수로 만들어 쉽게 재사용할 수 있도록 만들어보자
데이터의 전처리를 전체적으로 호출하는 함수는 transform_features()이고 Null 처리, 포매팅, 인코딩을 수행하는 내부 함수로 구성할 수 있다.

위에서 만든 transform_features() 함수를 이용해 다시 원본 데이터를 가공해보려고 한다.

train_test_split() API를 이용해 별도의 테스트 데이터 세트를 추출한다. 이때 테스트 데이터 세트 크기는 전체의 20%로 한다.

'Machine learning' 카테고리의 다른 글
| [머신러닝] 평가 (0) | 2021.07.27 |
|---|---|
| 머신러닝 개념 (0) | 2021.07.11 |


댓글